正所谓怕什么来什么,这是知名的“墨菲定律”。Java基础涵盖各个方面,敢说Java基础扎实的人不是刚毕业的学生,就是工作N年的程序员。工作N年的程序员甚至也不敢人人都说Java基础扎实,甚至精通,往往只是“无他唯熟尔”——熟手而已。
IO这块我确实怕,它不难,只有两个方面:输入/输出。但你说它用得多不多,我相信没有你写的并发多,并发往往是处处可见,写着写着就熟了,而IO却往往只是某个模块会涉及,所以也就并不是每个程序员在开发维护自己的模块时都会用到有关IO的API,而碰到的时候常常陷入窘迫,不知道怎么写。
我想研究IO这块愿意正是想巩固自己的Java基础,并希望能成为精通Java的那个人。 本文作为Java IO系列的开篇,首先要介绍几个概念:字节与字符。原因在于,Java IO的API分为字节流和字符流,了解什么是字节和字符有助于我们后续IO的理解。
字节(Byte)
计算机中存储数据的一个单位。比它小的是位(bit,也叫比特),这是在计算机中数据存储的最小计量单位,1位存放的是二进制的数据0和1,如下所示。
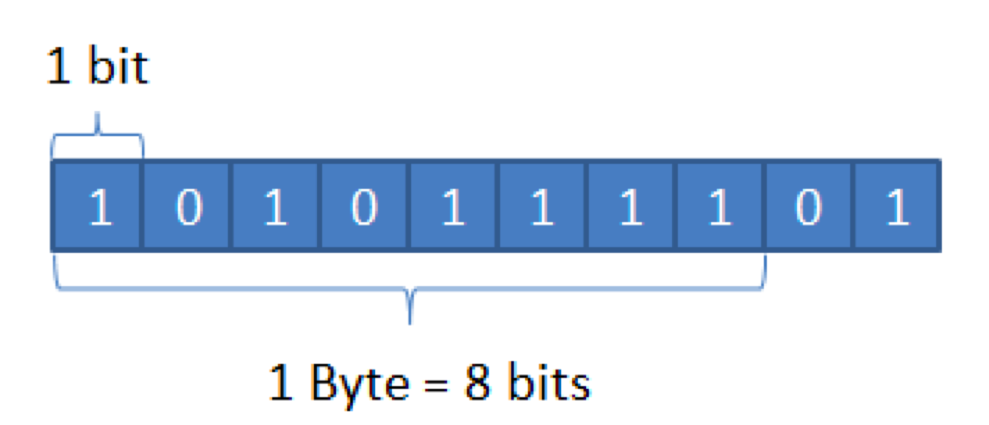
当然比字节更大的是KB(千字节),1KB = 1024B,再到后面就是MB(兆字节),1MB = 1024KB,GB、TB……
Java中有用于表示字节的数据类型——byte,再次不妨回顾下有关在Java中有关byte的一些知识。
前面提到1个字节等于8个二进制位,那么也就是说1个字节能表示的最大数为[0, 255](闭区间),但是,在Java中byte类型是有符号型的,也就是说在它的最高位是符号位。也就是说除去最高位符号位,还剩下7个二进制位,那么7个二进制所能表示的最大数为[0, 127],这是正数,加上最高位为1表示负数时,byte型数据类型所能表示的最大数为[-127, 0],也就是说byte型的数据范围是[-127, 127],真的是这样吗?错了。上面的分析是错误的。Java中byte型数据类型的取值范围为[-128, 127]。
错误的原因是没有考虑到计算机中数值存储的编码问题。所以这又会继续延伸到原码、反码、补码的概念。
- 原码:最高位表示符号位,0表示正数,1表示负数,其余位表示真实数值。前面的错误分析正是将计算机中数值存储定义为了原码,所以才会得到Java中byte型数据类型的取值范围是[-127, 127]。
- 反码:同样最高位表示符号位,正数的反码与原码相同,而负数的反码除符号位外,其余位取反。
- 补码:同样最高位表示符号位,正数的反码与原码相同,而负数的补码除符号位外,其余位取反+1。计算机中数值的存储正是补码。
可以通过程序来观察体会,计算机中数值存储是通过补码来存储的。
System.out.println("正数3的二进制原码为:11,其补码与原码相同为:" + Integer.toBinaryString(3));System.out.println("负数-3的二进制原码为:111,其补码与为(int型占4bytes=32bits,只看最后的3位):" + Integer.toBinaryString(-3) + "(不信将最后三位补码-1取反得到原码)"); 通过运算结果可以看到,计算机中的数值确实是以补码方式存储的。

在了解了原码、反码、补码,以及知道计算机中数值是以补码方式存储过后,现在回到Java中byte型数据类型的范围上来。就算是以补码方式的存储,可以确定的是在byte型数组中正数(最高位为0)的范围是[0, 127]一共128个数,那么负数(最高位为1)的原码范围则是[-127, -0],二进制也就是[11111111, 10000000],注意这是原码,并且这个地方有点冲突,也就是出现了-0这种表示,这显然是不合理的或者说0已经在正数中已经包括了,在这里实际上byte型数组做了一定的处理,也就是把把-0的补码当做了-128,-0的原码是10000000,它的反码则是11111111,它的补码则还是10000000,反码+1过后需要进位,但是最高位表示符号位,所以被挤掉了,总之此时负数的范围则是[-128, 0),byte型数组的范围则是[-128, 127]。原因是由于-0和0表示的都是0为避免浪费,将-0表示为-128扩大了范围。
这一段我们通过字节(Byte)这种表示计算机数据存储的单位,延伸了Java中byte型数据类型的取值范围,进而回顾了计算机中数值存储的编码方式,应该是能更好的理解字节这个概念。下面将介绍什么又是字符。
字符(Char)
字符表示文字和符号。人与人之间通过人类语言进行沟通,计算机通过二进制来进行沟通,当人-计算机-人,中间多了计算机的媒介过后,中间就需要计算机对我们人类的语言符号“编码”进行传输,而计算机-人这个过程又称之为“解码”。这有点类似“加密”“解密”的过程。
在计算机刚出现的时候只能传输英文字符,这里的传输包括是显示和存储,前面提到要进行编码存储,既然要编码就需要一张表来表示A是什么,B是什么,就好比摩斯密码中的密码本一样。那时的“码表”也就是编码方式叫做ASCII。

计算机继续在发展,需要发展到其他国家和地区,此时就需要对汉字、日文、韩文等进行编码,但原有的ASCII肯定不能满足,它的设计是包括了英文和符号,此时就出现了ANSI编码(也叫做ASCII扩展),这实际上是一种规范,一种本地化的规范编码,例如在中文操作系统中ANSI代表的就是GB2312编码(当然也有它的扩展叫做GBK编码),在日文操作系统中ANSI代表的就是JIS等等。ANSI编码采用2个字节来表示一个字符(范围在0x80-0xFF),两个字节也就是16个二进制位,理论上可以表示216个字符,当然这需要减去0x00-0x79这个范围,这就能表示很多很多的字符了。GB2312编码也就才表示了6000多个常用汉字。不过这种编码方式还是带来了新的问题,这只是做了本地化,也就是说在GB2312的编码环境下,无法对日文进行编码。所以还需要做国际化。
随着计算机的继续发展,国际化越来越重要这当然也就包括编码方式的改变,为避免ANSI不兼容的状况,又制定了新的编码规则——UNICODE。在Java中使用的就是UNICODE编码,这符合Java跨平台的特性,这也就解释了Java中char字符的数据类型占用的是2个字节,因为Java使用UNICODE编码,而UNICODE是2个字节表示1个字符。UNICODE解决了不同语言在不同平台不兼容的情况,但也有一个小小的弊端,也就是稍微比前面两种要占空间,以UNICODE字符集在内存中存储的字符串我们称之为为“宽字节字符串”,实际上之后对于字符编码的工作就集中在了如何缩短字节空间上。 这里就着重介绍UNICODE编码,UNICODE编码之所以略占空间,是因为它使用2个字节来表示1个字符。就算是英文也是使用2个字节。而ACSII和ANSI则使用1个字节表示英文。空间的占用就体现在了这个地方,如下图所示。
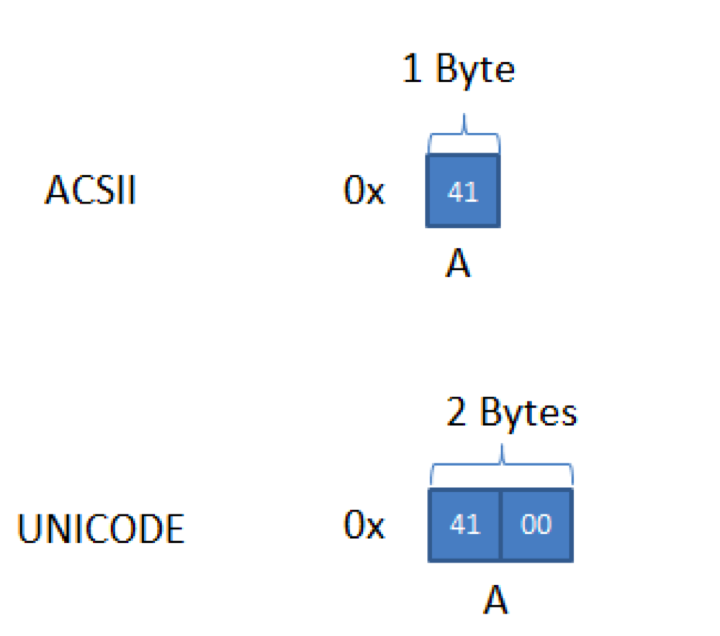
可以看出,这就白白地浪费掉了1个字节的空间,在这里实际上又可以继续延伸出有关计算机基础的知识,也就是在计算机中的数据在内存中的存储方式是大端模式(Big-Endian,也称高字节在前),还是小端模式(Little-Endian,也称低字节在前)。所谓大端模式就是高位字节在内存的低地址端,低位字节在内存的高地址端。而小端模式则是高位字节在内存的高地址端,低位字节在内存的低地址端。上图所示方式就是大端模式,可以看到低位字节跑到了地址的左边也就是高地址端。需要清楚的是Java中采用的是大端模式。
继续回到编码上来,由于UNICODE给任意字符都是采用的2个字节表示1个字符,会造成空间浪费,所以在UNICODE编码基础上,又出现了可变长编码的UTF-8编码,这种编码方式会灵活地进行字符的空间分配,不同字符所占用的内存空间不相同,在保证兼容性的同时,也保证了空间的最合理使用。
这就是Java IO的基础知识,为的是便于后面Java IO中有关字节流和字符流的更好理解。
这是一个能给程序员加buff的公众号
